缘起
三月份的时候,那时的我还很有志气地打算学习数据分析的,然而后来发现自己似乎把技能点点到前端上了。
数据分析的话要有数据呀,嗯,从网上获取数据吧。手动扒太累了,就写个小程序咯。
说起来接触Python还是因为认识的同学说想学爬虫,然后问我写爬虫用什么语言好。我百度了一下,似乎写爬虫都用Python,于是我就跟他讲,你学Python吧。后来又由于各种原因我也进了Python的坑。
那到底什么是爬虫呢?说白了就是自动浏览网页获取网页的自动化程序,其实我们常用搜索引擎就有爬虫技术,比如Google爬虫。至于为什么用Python写,刚刚就说了,大家都用这个写,学的话也容易上手。

我们平时访问网页,表面上就是输入网址-浏览网页-获取信息三步,因此最简单的爬虫就是不断重复这三步。
事实上,写爬虫这东西,其实并没有太多技术性。但想造出健壮的爬虫,其实并不容易的。爬虫与反爬虫的斗争,大家可以上知乎了解一下:知乎 - 有哪些有趣的反爬虫手段?
至于爬虫能干啥,请看:利用爬虫技术能做到哪些很酷很有趣很有用的事情?
所需模块
写一个最简单的爬虫,其实只需要这两个模块:
- urllib和urllib2
一看这个模块名就知道是URL相关的library。具体用法可以参看:
以下语句运行环境为Mac OS/Python2.7.13。
一开始就说了我们只需要模拟三个步骤:输入网址-浏览网页-获取信息。
输入网址
输入网址是为了获取网页,当然前提是要联网,我们可以先在交互式解释器中看看。
import urllib2
res = urllib2.urlopen("https://rimoe.xyz") # 打开网页https://rimoe.xyz
print res
print res.read() # 解析re,输出html格式
输出:
1 <addinfourl at 4436195304 whose fp = <socket._fileobject object at 0x10816f8d0>>
2 '<!DOCTYPE html>\n<html lang="en">\n <head>\n <meta charset="utf-8">\n <meta
http-equiv="X-UA-Compatible" content="IE=edge">\n …… </body>\n'
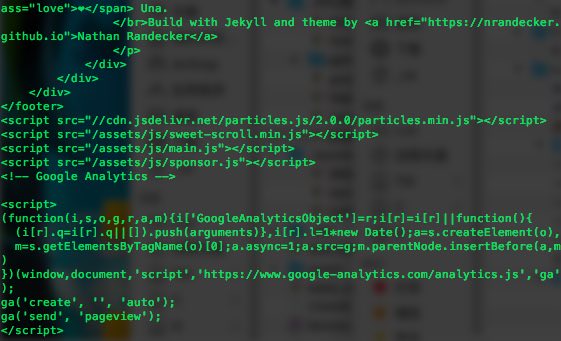
事实上,获取数据就是这么两句话。在某种意义上来说,网页经已爬下来了,爬虫已经写完啦。
先压抑内心的小兴奋,爬下来这么一堆东西有啥用呢?
当然,这样一堆字符看起来没啥用,但我们可以想办法从中间提取想要的元素。
浏览网页
我们日常浏览的网页一般都是浏览器解析过的标签文件,具体过程可以参考:
当然对于爬虫而言,我们希望程序输出的只包含我们需要的信息,因此我们需要对刚刚抓取的网页进行分析,也就是写程序来代替浏览器解释我们获取的文件(这里是html)。
这里就可以用到「正则表达式」这个东西了。
正则表达式,故名思义,就是规则的表达式,或者说是一个样例,通过这个样例我们可以从文本中规范准确地提取符合该样例的部分文本。
我们可以用正则表达式来提取能够匹配表达式的文本,正则表达式的匹配规则如下:
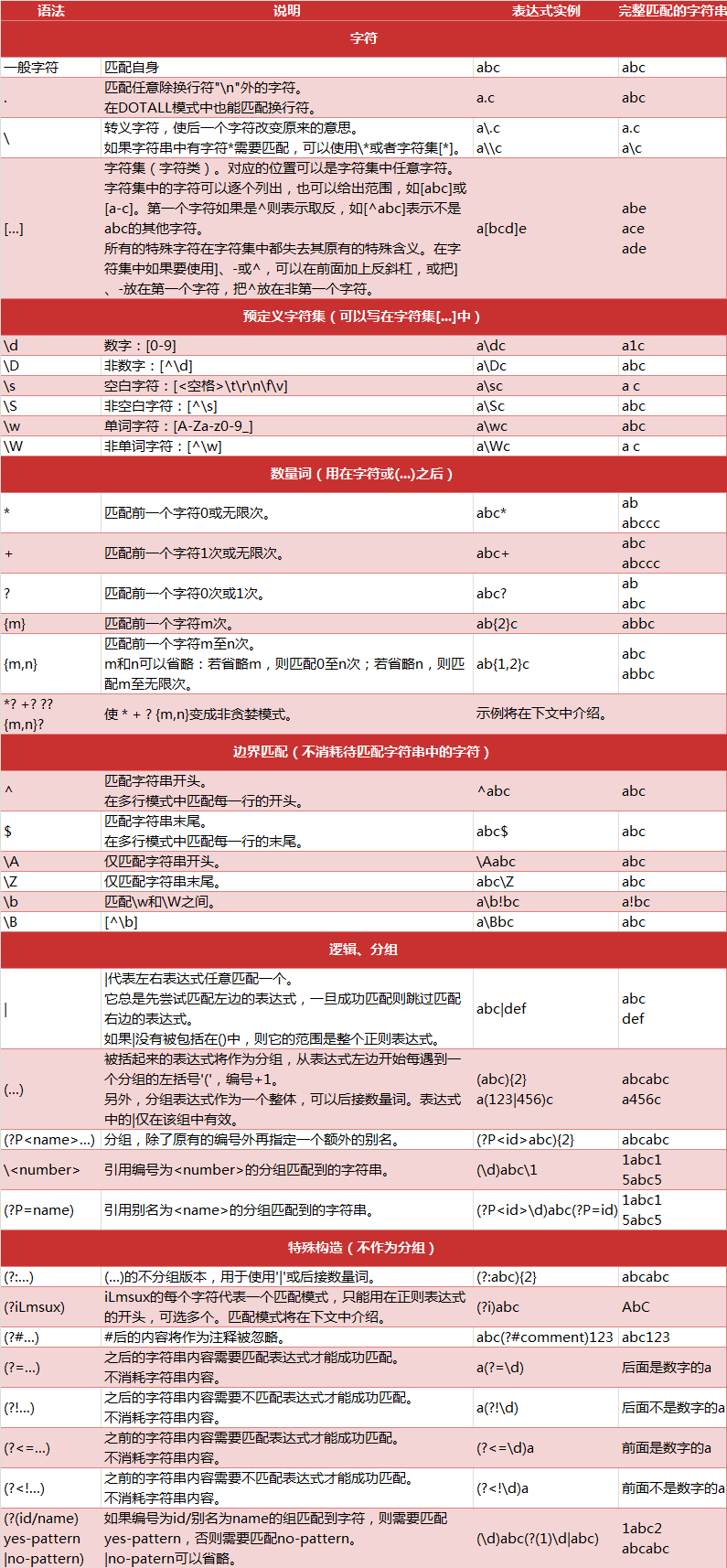
部分注解抄录如下:
(1)数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
(2)反斜杠问题
与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\”表示。同样,匹配一个数字的”\d”可以写成r”\d”。有了原生字符串,妈妈也不用担心是不是漏写了反斜杠,写出来的表达式也更直观勒。
图片引用及参考来自:静觅 - Python爬虫入门七之正则表达式
Python的re模块可以使用正则表达式匹配字符串:
import re
### 举例1
txt1 = 'rimoe,rimoe.xyz' #从txt1中搜索关键字'rimoe'
pattern1 = re.compile('rimoe') #用正则表达式生成pattern对象
re.findall(pattern1, txt1) #查找所有符合表达式的子串
### 举例2
txt2 = '1.rimoe\n2.Yue\n3.Luo\n' # 从txt2中提取列表内容
pattern2 = re.compile(r'\d+\.(.*?)\n')
re.findall(pattern2, txt2)
# 一般用r串作为参数
# 这里\d匹配数字(0~9),+表示匹配连续的数字,\.匹配字符'.'
# (.*?)匹配连续任意字符任意次,括号表示要提取的部分分组
# \n匹配回车,(.*?)\n表示任意字符匹配直到遇到回车停止匹配
输出
1 ['rimoe', 'rimoe']
2 ['rimoe', 'Yue', 'Luo']
比如对于我们刚刚爬下来的网页,我们想要提取网页的这一部分:
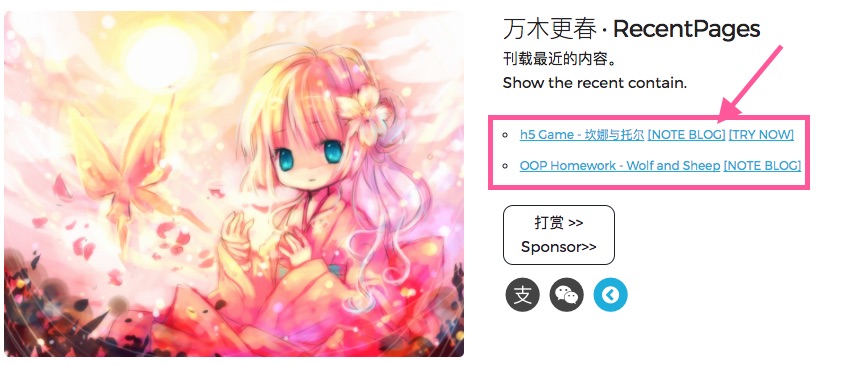
我们可以右击相应元素,点“检查”(审查元素)查看相对应的标签:
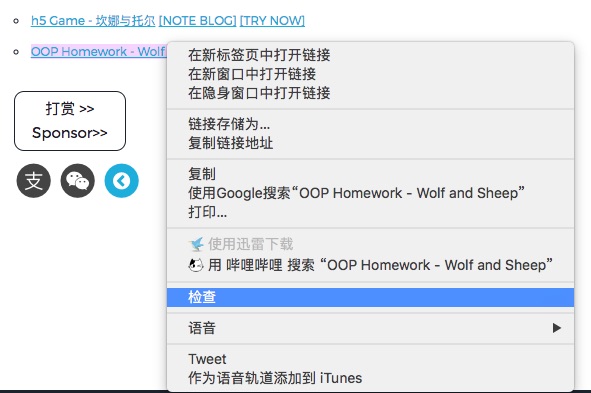
当然这里推荐Chrome,主要是因为好用加功能完善,在学习爬虫的道路上这个审查元素的功能和这个开发者选项框将会是你学习爬虫的好基友,弹出的框如下图:
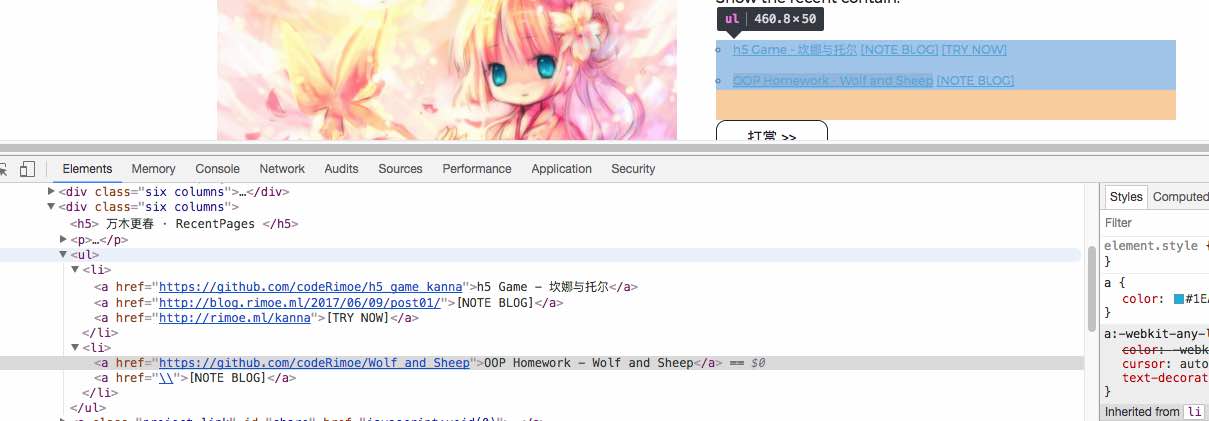
我们可以看到其实这一部分是一个列表标签,在我们刚刚抓取的网页里面也能找到:
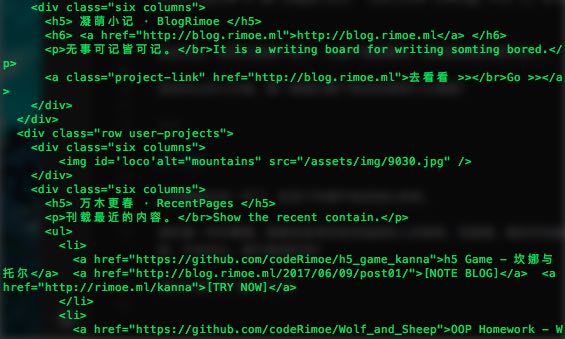
<ul>
<li>
<a href="https://github.com/codeRimoe/h5_game_kanna">h5 Game - 坎娜与托尔</a>
<a href="https://blog.rimoe.xyz/2017/06/09/post01/">[NOTE BLOG]</a>
<a href="https://rimoe.xyz/kanna">[TRY NOW]</a>
</li>
<li>
<a href="https://github.com/codeRimoe/Wolf_and_Sheep">OOP Homework - Wolf and Sheep</a>
<a href="\\">[NOTE BLOG]</a>
</li>
</ul>
我们用正则表达式来表示,分两次提取:
# 刚刚提取的网页返回res
import re
txt1 = res.read()
pattern1 = re.compile(r'<li>(.*?)</li>', re.S)
# 提取列表标签<li>
# re.S为DOCALL模式,该模式下字符'.'可以匹配回车'\n'
txt2 = re.findall(pattern1, txt1)
print txt2 # 打印出来看看是什么样子的吧~
pattern2 = re.compile(r'<a.*?href=(.*?)>(.*?)</a>', re.S)
for txt in txt2:
results = re.findall(pattern2, txt) # 逐项提取链接标签<a>
print 'Project:' # 格式化打印
for result in results:
print result[1]+':'+result[0]
print
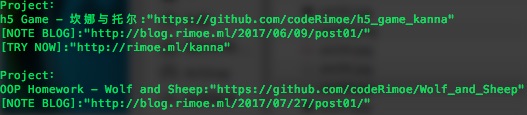
输出:
1 ['\n <a href="https://github.com/codeRimoe/h5_game_kanna">h5 Game - \xe5\x9d\x8e\xe5\xa8\x9c\xe4\xb8\x8e\xe6\x89\x98\xe5\xb0\x94</a> <a href="https://blog.rimoe.xyz/2017/06/09/post01/">[NOTE BLOG]</a> <a href="https://rimoe.xyz/kanna">[TRY NOW]</a>\n ', '\n <a href="https://github.com/codeRimoe/Wolf_and_Sheep">OOP Homework - Wolf and Sheep</a> <a href="https://blog.rimoe.xyz/2017/07/27/post01/">[NOTE BLOG]</a>\n ']
2 Project:
3 h5 Game - 坎娜与托尔:"https://github.com/codeRimoe/h5_game_kanna"
4 [NOTE BLOG]:"https://blog.rimoe.xyz/2017/06/09/post01/"
5 [TRY NOW]:"https://rimoe.xyz/kanna"
6 Project:
7 OOP Homework - Wolf and Sheep:"https://github.com/codeRimoe/Wolf_and_Sheep"
8 [NOTE BLOG]:"https://blog.rimoe.xyz/2017/07/27/post01/"

获取信息
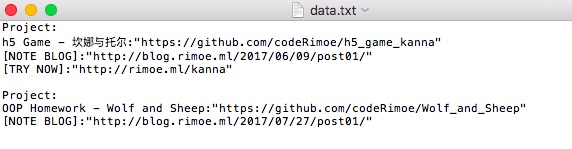
一般来说数据获取后,要保存到本地,对于列表一般保存为csv格式,这里我们就保存为普通的文本文件。
#将打印部分修改成保存文档
with open('data.txt','w') as file:
for txt in txt2:
results = re.findall(pattern2,txt)
file.write('Project:')
for result in results:
file.write('\n'+result[1]+':'+result[0])
file.write('\n')
总结
# -*- coding: utf-8 -*-
# Spider Lv1
import urllib2
import re
res = urllib2.urlopen("https://rimoe.xyz") # 打开网页https://rimoe.xyz
txt1 = res.read()
pattern1 = re.compile(r'<li>(.*?)</li>', re.S) # 提取列表标签<li>
txt2 = re.findall(pattern1, txt1)
pattern2 = re.compile(r'<a.*?href=(.*?)>(.*?)</a>', re.S)
with open('data.txt', 'w') as file:
for txt in txt2:
results = re.findall(pattern2, txt) # 逐项提取链接标签<a>
file.write('Project:') # 格式化输出
for result in results:
file.write('\n'+result[1] + ':' + result[0])
file.write('\n\n')
代码已发到Github - Spider。
爬虫的原理简单粗暴,除了这个简单的爬虫之外,其实还有一些简单易用的现成框架,有硬件条件的话,爬虫的威力其实更大。
当然有条件的话,最好的爬虫其实是人肉爬虫(滑稽)。
接下来如果有时间,会继续写完这个爬虫入门笔记系列。
2017.08.24 午后 于广州