缘起
昨晚回宿舍的时候,看到一对情侣在路边撒狗粮,就像这样:

然后我就想可不可以上微博看看有没有相亲的,嗯,好像还真有:

那不如用爬虫爬一份相亲列表出来吧,嘿嘿嘿。
import urllib2
site = urllib2.urlopen("http://weibo.com/u/3803639941?refer_flag=1001030001_&"
"nick=%E4%BA%8C%E6%AC%A1%E5%85%83%E4%BA%A4%E5%BE%80%E5"
"%B9%B3%E5%8F%B0&is_hot=1&noscale_head=1#_0")
print site.read().decode('gbk') # 以gbk方式解码
然而发现……没有妹纸呀……
仔细观察,发现打印出来的开头是这样的:
<head>
<meta http-equiv="Content-type" content="text/html; charset=gb2312"/>
<title>Sina Visitor System</title>
</head>
访客系统……也就是说跳转到登录的网页了,需要登录才可以访问。
对于这种情况,我们可以有两个办法:
- 让爬虫自己登录
- 手工登录,然后爬虫使用cookie
在这篇文章里,我们手工登录获取cookie,然后使用cookie访问网页,至于第一种方法,后续的文章再做讨论。
运行环境
之前也说过了,这里语句运行环境都为Mac OS/Python2.7.13。
获取cookie
维基百科:Cookie,中文名称为“小型文本文件”或“小甜饼”,指某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。
平时我们PC上用微博时,在一次登录后,我们后续访问就可以不用登录了,其实就是本地存储了登录状态,请求网页时发送本地的cookie即可表明账户登录状态。
利用Chrome的开发者工具可以很方便地获取cookie。
如图,在Network中查看提交的Header,我们可以看到长长的一串字符,在访问网页时,我们只要提交这个cookie,就可以使用登录状态访问网页啦。
这个cookie在登录后持续有效直到退出账户或该次登录失效。
配置请求头
之前写API调研究的时候也提到了HTML请求方式和Header。
具体可以查阅HTTP教程
我们在这里尝试使用urllib2提交请求头。
import urllib2
url = ("http://weibo.com/u/3803639941?refer_flag=1001030001_&"
"nick=%E4%BA%8C%E6%AC%A1%E5%85%83%E4%BA%A4%E5%BE%80%E5"
"%B9%B3%E5%8F%B0&is_hot=1&noscale_head=1#_0")
cookie = 'SINAGLOBAL=balabala' # 输入cookie
headers = {'cookie': cookie}
request = urllib2.Request(url, headers=headers)
# 将URL、Header打包请求,当然这里还可以有别的参数
# class urllib2.Request(url[, data][, headers][, origin_req_host]\
# [, unverifiable])
response = urllib2.urlopen(request)
# 提交请求并获取响应
print response.read()
返回:
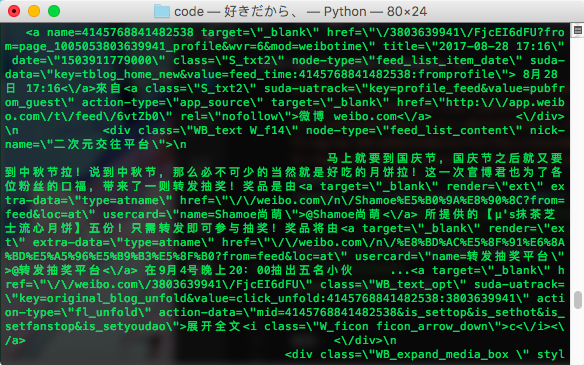
好啦,接下来就是正则表达式的事情了。
使用BeautifulSoup提取信息
可是,正则表达式用起来十分不方便,还容易出错,一不小心格式就调不好,还有可能连错在哪都搞不清楚。
我们知道在HTML DOM中HTML的所有内容被都视为一种节点,其实我们只要知道节点的路径,就可以快速获取该节点提取相应信息。BeautifulSoup就可以基于这个原理用于快速获取html里的信息。
这里就可以尝试使用BeautifulSoup来代替正则表达式,体会一下鸟枪换炮的感觉。
据说bs4对Python3并不友好,但我们用的是python2就不管那么多了。
当然使用前我们要先安装一下bs4这个库,另外我们还需要lxml这个库的支持(用于解析html,类似的还有html5lib以及python自带的html.parser):
pip install bs4
pip install lxml
观察源码,我们可以发现,微博的网页其实是使用一个js函数FM.view(json)来展示的,html存在一个json格式中:
FM.view({
"ns" : "",
"domid" : "xxx",
"css" : ["..."],
"html" : "balabala"
})
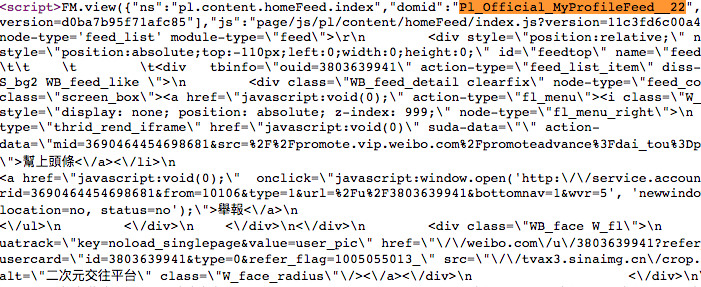
再仔细观察,可以发现,主页微博的html是在domid为Pl_Official_MyProfileFeed__22的json中的,我们先用正则表达式把这部分内容提取出来。使用json模块解析其中的html属性,就得到用户主页微博的html文本。
#承接上一节response为返回内容
import re
import json
html = response.read()
pattern = re.compile(r'"domid":"Pl_Official_MyProfileFeed__22",(.*?)\)</script>',re.S)
webres = re.findall(pattern,html)[0] #用正则表达式提取包含内容部分
webres_json = json.loads('{'+webres) #解析json字符串,前面要补充`{`字符
webres_html = webres_json['html']
打印出来是这样的:
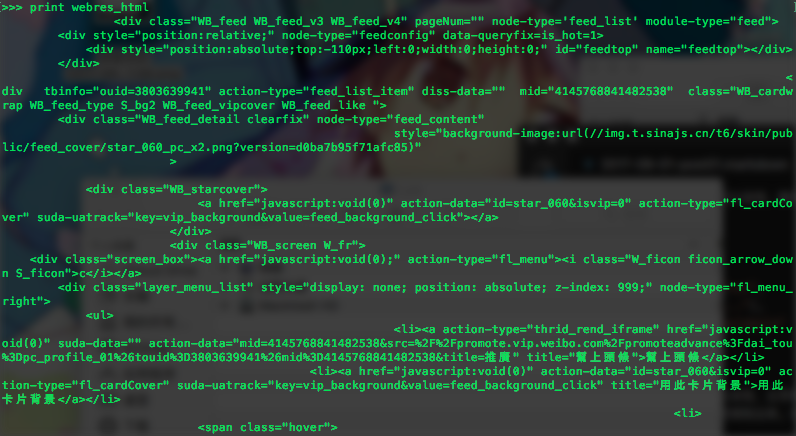
接下来我们用BeautifulSoup对html文本进行分析,首先看看造出来soup是怎样的呢?
#使用BeautifulSoup对webres_html进行分析
import lxml
from bs4 import BeautifulSoup as bs
soup = bs(webres_html, 'lxml') # 构建Soup
print soup
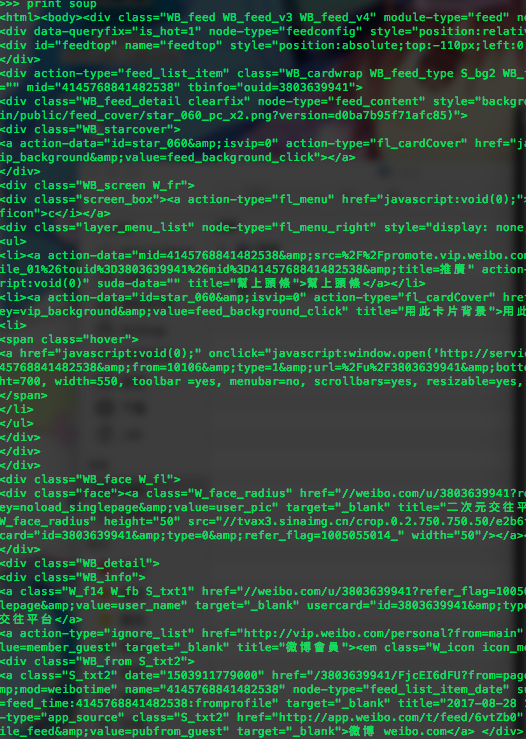
打印出来的东西十分整齐,真是一个beautiful的soup,看着就很舒服。使用contents可以逐级分析html下的标签元素。
print soup.contents
print soup.html.body.contents
通过源码我们大概知道,在每条单独微博都在一个class为”WB_dertail”的div里,使用find_all的方法,得到所有符合条件的标签,以数组形式返回,然后我们,将微博里的含信息标签全部提取出来。
# 微博每张图片有id,缩略图URL、URL分别为以下格式:
# http://wx4.sinaimg.cn/mw690/(pic_id).jpg # URL
# http://wx4.sinaimg.cn/square/(pic_id).jpg # 缩略图URL
infos = soup.find_all(class_="WB_detail")
pattern_pic = re.compile(r'pic_id=(.*)')
for info in infos:
Stxt=""
try:
txts = info.find_all(class_="WB_text W_f14")[0].contents
pics = info.find_all('li')
for txt in txts:
try:
for txtc in txt.contents:
Stxt+=txtc # 对于链接文本,提取其内容
except:
Stxt+=txt # 否则原样输出
for pic in pics: # 得到图片URL
picid = re.findall(pattern_pic, pic.get('action-data'))
print "http://wx1.sinaimg.cn/mw690/" + picid[0] + '.jpg'
except:
pass
print Stxt
打印出来的效果:

关于BeautifulSoup的用法,可以参考静觅 - Python爬虫利器二之Beautiful Soup的用法,此外个人觉得XPath更好用,具体可以参考Python爬虫利器三之Xpath语法与lxml库的用法。
写文件
写文件当然容易,但要保存图片的话,就需要用到imghdr模块。
imghdir的what模块可以返回图片的文件格式。
from imghdr import what
import urllib2
pic_url = 'http://rimoe.xyz/assets/img/9030.jpg'
save_dir = '/Users/_nA/Desktop/' # 存储路径
photo = urllib2.urlopen(pic_url).read()
pic_type = what('', h=photo) # 判断图片格式
if not pic_type : # 若无法识别格式返回None
pic_type = ''
name = save_dir + 'pic.' + pic_type
with open(name, 'w') as f:
f.write(photo)
按页数依次爬取
这样下来我们只能抓取一部分,妹子根本不够看,那我们就多抓几页:
我们可以看到微博主页的URL可以设置URL参数,这里简单地修改URL的page参数即可。
page = 1
url = ("http://weibo.com/u/3803639941?is_search=0&visible=0&is_all=1&is_tag=0&"
"profile_ftype=1&page=%d" % page)
最后程序可以写成函数,写个循环就开始跑了。
跑出来结果如下:

结尾
嗯,可是这东西爬下来关我什么事呢?
写这篇文章的人真是有够无聊了,还不如去看二次元的妹子(误)。

代码已发到Github - Spider。
2017.09 于广州