某魔法学院
今天校庆,和小伙伴出去吃了顿火锅有点高兴,所以写了一篇blog。(然而作业还没写完……)
然而期中小长假结束了,有点不开心。
如果坐上来自己动就好了
最近尝试爬知网上的一些数据(专利数据库),他的界面是这个样子的。
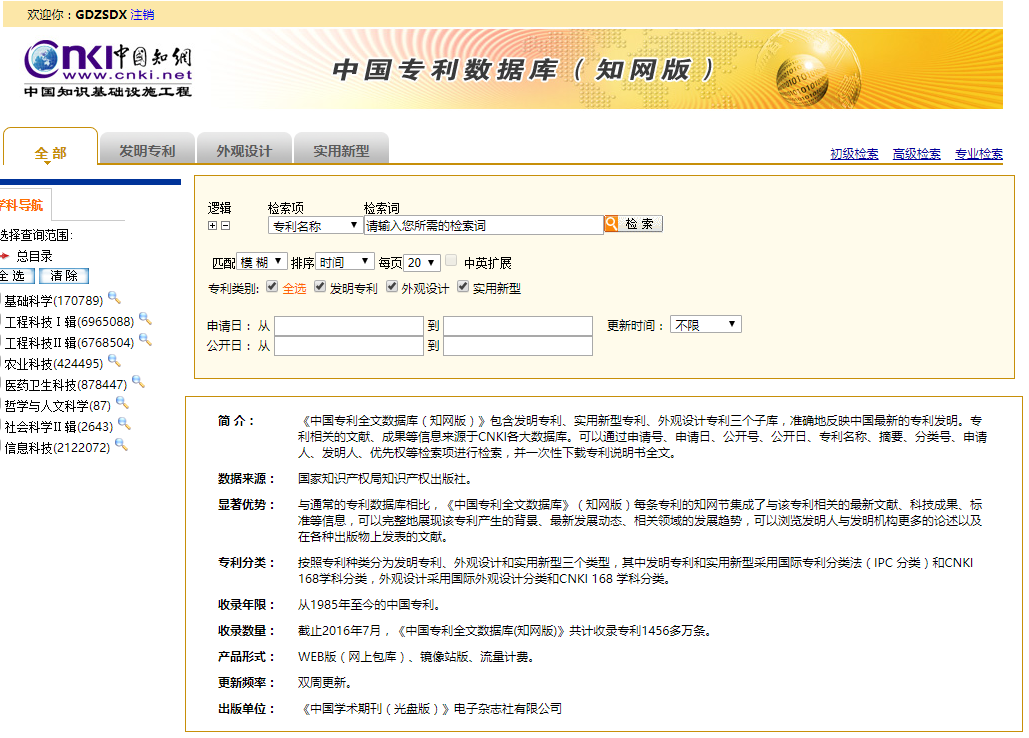
嗯,那我们首先要进行查询才能获得数据,我们输入以下条件进行搜索。
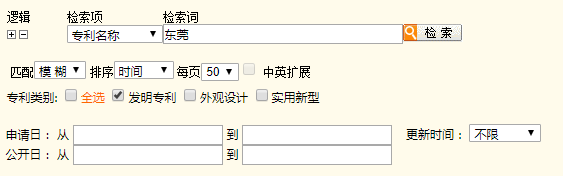
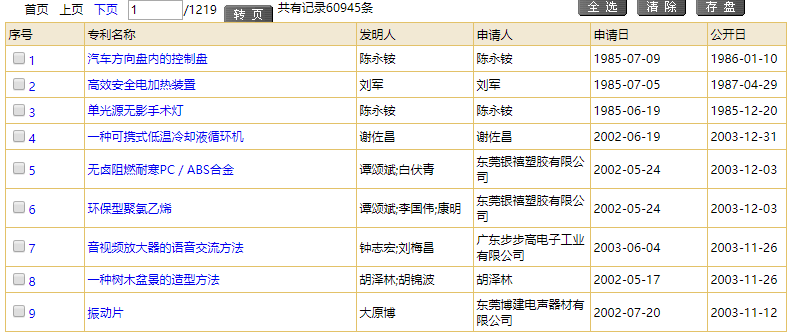
得出一堆结果,点开发现是一些有规律的表格。
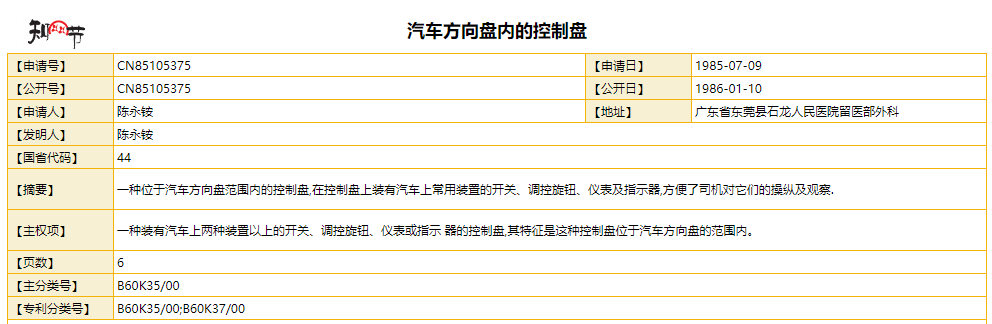
如果我们能让浏览器自动搜索,不就可以让他一直获取网页的数据了吗?
Selenium简介与配置
是的, 因此我们今天试着用selenium这个框架。说起这个框架,其实这还是我一个接触的爬虫框架,当时也正是因为觉得这个框架很酷才继续研究爬虫的。下一篇文章将会介绍我第一次学习爬虫时曲折旅途,其中就还会提到selenium。
Selenium用于编写自动控制浏览器的脚本,除了在爬虫上有应用,在并发模拟上也有应用。
配置selenium需要以下几个步骤:
安装selenium模块 配置driver
安装selenium模块
用对应python的pip(或conda)安装:
pip install selenium
配置driver(Chrome)
各种浏览器有各自的driver,这里推荐使用chrome的driver。
首先要下载(地址)对应Chrome版本的chromedriver,版本映射表如下:
| v2.33 | v2.32 | v2.31 | v2.30 | v2.29 | v2.28 |
| v60-62 | v59-61 | v58-60 | v58-60 | v56-58 | v55-57 |
| v2.27 | v2.26 | v2.25 | v2.24 | v2.23 | v2.22 |
| v54-56 | v53-55 | v53-55 | v52-54 | v51-53 | v49-52 |
| v2.21 | v2.20 | v2.19 | v2.18 | v2.17 | v2.13 |
| v46-50 | v43-48 | v43-47 | v43-46 | v42-43 | v42-45 |
| v2.15 | v2.14 | v2.13 | v2.12 | v2.11 | v2.10 |
| v40-43 | v39-42 | v38-41 | v36-40 | v36-40 | v33-36 |
| v2.9 | v2.8 | v2.7 | v2.6 | v2.5 | v2.4 |
| v31-34 | v30-33 | v30-33 | v29-32 | v29-32 | v29-32 |
参考自selenium之 chromedriver与chrome版本映射表(更新至v2.33)
这里一定要注意安装与你的Chrome版本对应的driver,不然会报错(这是个大坑)。
把chromedriver放在环境变量的任一路径下即可。
或者将chromedriver放在chrome的目录下,并将chrome的目录添加进去环境变量也是可以的。
打开Python,测试一下:
from selenium import webdriver
driver = webdriver.Chrome() # 若配置成功,将会弹出Chrome浏览器界面
driver.get('https//www.sysu.edu.cn') # 浏览中大的网站
driver.close() # 关闭webdriver
这样,selenium的环境就配置好了。
数据获取思路
我们思考一下我们搜索的流程。
- 打开专利数据库.
- 输入条件,搜索。
- 点击专利链接进入专利页面。
- 获取专利表格数据。
接下来我们将会按以上流程依次获取数据。
使用Selenium操作浏览器
Selenium作为一个自动化的框架,用在爬虫技术上最好的优点就是十分弱智,一句话概括就是“写一个Script来控制浏览器”,操作基本上只有两个:
- 创建一个webdriver对象(其实就是浏览器)
- 通过webdriver的函数控制浏览器
在测试Chrome的时候我们就知道怎么让webdriver打开一个网页了,用webdriver.get(url)就行了。
from selenium import webdriver
search_whe = u'地址'
search_key = u'东莞'
search_type = 0
url = 'https//dbpub.cnki.net/grid2008/dbpub/brief.aspx?id=scpd'
driver = webdriver.Chrome() # 创建一个webdriver,接下来的操作都基于此
driver.get(url) # 用get的方法打开网站
要对webdriver进行控制,每个操作只要执行两步:
- 获取网页元素(Xpath)
- 操作网页元素
比如我们要在输入框输入,首先要获取要输入的文本框元素这一个对象,获取元素可以用webdriver.find_element_by_xpath(xpath)这个函数。
这里提到Xpath,那到底什么是Xpath呢?
这个就和我们上次提到BeautifulSoup很想,其实就是网页元素在网页的路径,我们通过Xpath可以准确定位一个元素在网页的位置(有点像我们OS的文件路径),当然其中还可以用一些匹配符号什么的,也能获取元素列表,至于Xpath的具体含义我们先不细说,以后有机会也可以写一篇文章(或者可以参考:静觅 - Python爬虫利器三之Xpath语法与lxml库的用法),在这里介绍一个获取Xpath的快捷方法。
在Chrome里,对要获取的元素右键-检查元素,弹出开发者工具,对元素的html标签右键,复制Xpath即可得到对应的Xpath,如图的文本框元素Xpath为//*[@id="Text1"]。
获取了Xpath我们就可以获取元素,然后对元素进行操作,比如这里在文本框中输入关键词“东莞”。
inbox = driver.find_element_by_xpath('//*[@id="Text1"]') # 获取元素
inbox.clear() # 清空文本框内容
inbox.send_keys(u"东莞") # 在已有内容后添加文本
我们可以发现文本框内容变成了东莞。
其他操作类似,具体方法可以参考:
# 此处接上,driver已经打开知网数据库网页。
# 获取元素
# inbox:输入文本框 buton:搜索按钮 where:检索项 pages:每页条目 types:专利类别
inbox = driver.find_element_by_xpath('//*[@id="Text1"]')
buton = driver.find_element_by_xpath(
'//*[@id="Table6"]/tbody/tr[1]/td[3]/table/tbody/tr/td/input')
where = driver.find_element_by_xpath('//*[@id="Select1"]')
pages = driver.find_element_by_xpath('//*[@id="Table8"]/tbody/tr/td/select[3]')
types = [
driver.find_element_by_xpath('//*[@id="专利类别1"]'), # 专利发明
driver.find_element_by_xpath('//*[@id="专利类别2"]'), # 外观设计
driver.find_element_by_xpath('//*[@id="专利类别3"]') # 实用新型
]
inbox.clear() # 清空文本框内容
inbox.send_keys(search_key) # 在已有内容后添加文本
for t in types:
t.click() # 清除所有已选专利类别
types[search_type].click() # 选择需要的专利类别
Select(pages).select_by_value('50') # 设置每页50条专利
Select(where).select_by_value(search_whe) # 设置按地址搜索
buton.click() # 点击搜索按钮
获取专利数据
接下来就只需要定位专利条目,获取链接地址,然后提取相应链接里的信息。
定位链接的话,我们仍然可以使用Selenium了啦,然后可以使用get_attribute这个方法来获取元素的属性。
a = '//*[@id="contentBox"]/table/tbody/tr[2]/td[2]/a'
txt = a.get_attribute("href")
有很多个链接的话,我们可以看到他的Xpath是有规律的,于是写一个循环就可以了。
获取了链接,之后我们可以就用正则表达式来获取专利的具体信息了,另外这里用requests代替urblib和urllib2,但其实作用是差不多的。
爬虫对象与多线程
在Spider_Lv3的代码里,将爬虫写成一个类,这样在我们调用时可以比较方便一些,每个小步骤也写成对应函数,因此在代码修改时可以更加简单。
为了可以一边定位网页链接同时也一边获取网页数据,代码中使用了多线程,过程中了解到有人认为Python的多线程比较鸡肋,此次使用多线程到底有没有提高效率暂时也没有深究,多线程作为一个待学习的内容将来再研究。
代码已发到Github - Spider。
2017.11.12 晚 于广州